Anyhoo, just got back from a whistle stop tour of Toronto and New York, and familiarising myself with the subtle differences between us English speaking nations: "It's the little differences... Do you know what they call a Quarter Pounder with cheese?", "Royale with Cheese!".

Despite the general lack of sleep, overeating and drinking, through excessive coffee consumption I did manage to get quite a lot crammed into my 5 days.
Met some really smart guys from Apprenda, who have a very interesting offerings in the PaaS space. In particular their private PaaS solution addresses a lot of the underlying problems in IT organisations: i.e. from being infrastructure centric. They stitch together the infrastructure into a grid using their peer-to-peer fabric, which creates some interesting options in managing message flow.

It looks very slick, and for web apps it's a no brainer, but my challenge is that I face is a legacy of mid-range and mainframe apps, and all the [cultural] baggage that comes along with that... Any thoughts as to how to start the transition?
I also spent some time talking to the Hadoop distro vendor MapR to bounce around my IT Operations Analytics concept I'm trying to get some traction on. They also have a really interesting offering, though their marketing has let them down up to now. Basically their approach is not to champion particular products within the Hadoop ecosystem, rather they will support anything on top of their MapR-FS file system.
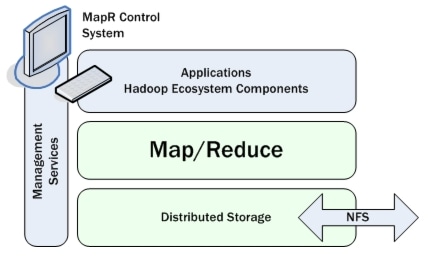
With MapR-FS they've basically ripped out HDFS and replaced with a file system that addresses some of the key issues in HDFS, yet still support the HDFS APIs:
- The NameNode is a bottle neck
- Start times on a NameNode recovery are lengthy
- Lack of POSIX compliance
- Supporting legacy UNIX/Linux apps
- Small files support
I'm about to start kicking the tyres with MapR, so will report back once I have a bit more experience, but I'm impressed with what I've seen thus far.
Signing off.
No comments:
Post a Comment